The Jordan Clarkson Effect
Using Pandas, Numpy, and Sklearn to create a machine learning model that would predict whether or not a player is a starter.
Project Objective
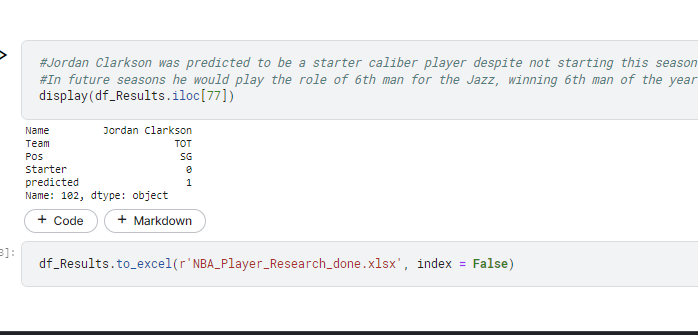
The purpose of this project was to explore the effectiveness of Machine Learning models of predicting whether or not a player was an NBA starter based off data from Basketball-Reference.com. A sub-focus of the project was to see whether or not Jordan Clarkson, who looked like a much better player on the Jazz than the Cavs, would be predicted as a starter or bench player based off the models.
Project Outcome
The model that produced the best results was the Logistic Regression model, though Random Forest Classifier warehouse an extremely close second. The model had a precision of 74%, meaning that if a player was a starter in the data the model would also predict them to be a starter 74% of the time. However, the model only had a recall of 48%, meaning that if a player was a backup in the data the model would also predict them to be a backup only 48% of the time.
One conclusion could be that the gap between lower end starters and higher end bench players are close enough that the model was unable to distinguish the difference. Another conclusion that could be drawn is that by merging player positions all into the same machine learning model it muddied what separates a starter and bench player. For example, Rudy Gobert is great at rebounding but doesn't even attempt threes. This is acceptable because he is a center. But if a Point Guard was unable to shoot the three, he wouldn't likely have the other skills necessary to stay on the floor.
My conclusion on the results is that the outcome provides good insight onto further research that needs to be done. The results show that there are some underlying stats that provide insight into what makes a player a starter. But it would be best practice to build out a model to compare this model against that would break down the players by position (or at least by front court and back court). This would require more data (at least the past 5 years, possible the past 10) to get adequate sample size.
What I learned
In future models and a revision of this model I need to find ways to incorporate more data. Having only one season of data resulted in 148 starters and 248 backups after filtering players out for lack of games played and lack of minutes per game (sample size issues). Using the previous 5 seasons of player data would have provided a much better sample size while also having the parameters of the game kept relatively the same (i.e., not a lot of rule changes or dramatic difference in style of play). To make this model work for a single season, I made sure to use cross-validation. However, it would have been better to use both cross validation and multiple seasons of data.